-
1 блок программного обеспечения системы контроля в реальном масштабе времени станций слежения, управления и связи с космическим аппаратом
Engineering: real-time DSN monitor software assemblyУниверсальный русско-английский словарь > блок программного обеспечения системы контроля в реальном масштабе времени станций слежения, управления и связи с космическим аппаратом
-
2 SRU
shop-replaceable unit — блок, заменяемый в мастерской -
3 отказ
отказ
Нарушение способности оборудования выполнять требуемую функцию.
Примечания
1. После отказа оборудование находится в неисправном состоянии.
2. «Отказ» является событием, в отличие от «неисправности», которая является состоянием.
3. Это понятие, как оно определено, не применяют коборудованиюобъекту, состоящему только из программных средств.
4. На практике термины «отказ» и «неисправность» часто используют как синонимы.
[ГОСТ ЕН 1070-2003]
[ ГОСТ Р ИСО 13849-1-2003]
[ ГОСТ Р МЭК 60204-1-2007]
отказ
Событие, заключающееся в нарушении работоспособного состояния объекта.
[ ГОСТ 27.002-89]
[ОСТ 45.153-99]
[СТО Газпром РД 2.5-141-2005]
[СО 34.21.307-2005]
отказ
Событие, заключающееся в нарушении работоспособного состояния машины и (или) оборудования вследствие конструктивных нарушений при проектировании, несоблюдения установленного процесса производства или ремонта, невыполнения правил или инструкций по эксплуатации.
[Технический регламент о безопасности машин и оборудования]EN
failure
the termination of the ability of an item to perform a required function
NOTE 1 – After failure the item has a fault.
NOTE 2 – "Failure" is an event, as distinguished from "fault", which is a state.
NOTE 3 – This concept as defined does not apply to items consisting of software only.
[IEV number 191-04-01]
NOTE 4 - In practice, the terms fault and failure are often used synonymously
[IEC 60204-1-2006]FR
défaillance
cessation de l'aptitude d'une entité à accomplir une fonction requise
NOTE 1 – Après défaillance d'une entité, cette entité est en état de panne.
NOTE 2 – Une défaillance est un passage d'un état à un autre, par opposition à une panne, qui est un état.
NOTE 3 – La notion de défaillance, telle qu'elle est définie, ne s'applique pas à une entité constituée seulement de logiciel.
[IEV number 191-04-01]Тематики
- безопасность в целом
- безопасность гидротехнических сооружений
- безопасность машин и труда в целом
- газораспределение
- надежность средств электросвязи
- надежность, основные понятия
Обобщающие термины
EN
DE
FR
отказ (failure): Событие, заключающееся в нарушении работоспособного состояния объекта
[ ГОСТ 27.002-89, статья 3.3].
Источник: ГОСТ Р 52527-2006: Установки газотурбинные. Надежность, готовность, эксплуатационная технологичность и безопасность оригинал документа
3.5 отказ (failure): Прекращение способности элемента исполнять требуемую функцию.
Примечания
1 После отказа элемент становится неисправным.
2 Отказ является событием в отличие от неисправности, которая является состоянием.
Источник: ГОСТ Р 51901.5-2005: Менеджмент риска. Руководство по применению методов анализа надежности оригинал документа
3.3. Отказ
Failure
Событие, заключающееся в нарушении работоспособного состояния объекта
Источник: ГОСТ 27.002-89: Надежность в технике. Основные понятия. Термины и определения оригинал документа
3.4 отказ (failure): Утрата изделием способности выполнять требуемую функцию.
Примечание - Отказ является событием в отличие от неисправности, которая является состоянием.
Источник: ГОСТ Р ИСО 13379-2009: Контроль состояния и диагностика машин. Руководство по интерпретации данных и методам диагностирования оригинал документа
3.2 отказ (failure): Утрата объектом способности выполнять требуемую функцию1).
___________
1) Более детально см. [1].
Источник: ГОСТ Р 51901.12-2007: Менеджмент риска. Метод анализа видов и последствий отказов оригинал документа
3.29 отказ (failure): Событие, происходящее с элементом или системой и вызывающее один или оба следующих эффекта: потеря элементом или системой своих функций или ухудшение работоспособности до степени существенного снижения безопасности установки, персонала или окружающей среды.
Источник: ГОСТ Р 54382-2011: Нефтяная и газовая промышленность. Подводные трубопроводные системы. Общие технические требования оригинал документа
3.1.3 отказ (failure): Потеря объектом способности выполнять требуемую функцию.
Примечания
1. После отказа объект имеет неисправность.
2. Отказ - это событие в отличие от неисправности, которое является состоянием.
3. Данное понятие по определению не касается программного обеспечения в чистом виде.
[МЭК 60050-191 ][1]
Источник: ГОСТ Р 50030.5.4-2011: Аппаратура распределения и управления низковольтная. Часть 5.4. Аппараты и элементы коммутации для цепей управления. Метод оценки рабочих характеристик слаботочных контактов. Специальные испытания оригинал документа
1. Отказ - событие, заключающееся в нарушении работоспособного состояния конструкций, зданий и сооружений.
2. Обследование конструкций - комплекс изыскательских работ по сбору данных о техническом состоянии конструкций, необходимых для оценки технического состояния и разработки проекта восстановления их несущей способности, усиления или реконструкции.
3.5 отказ (failure): Неспособность конструкции, системы или компонента функционировать в пределах критериев приемлемости.
[Глоссарий МАГАТЭ по безопасности, издание 2.0, 2006]
Примечание 1 - Отказ - это результат неисправности аппаратных средств, дефекта программного обеспечения, неисправности системы или ошибки оператора, связанной с ними сигнальной траекторией, которая и вызывает отказ.
Примечание 2 - См. также «дефект», «отказ программного обеспечения».
Источник: ГОСТ Р МЭК 62340-2011: Атомные станции. Системы контроля и управления, важные для безопасности. Требования по предотвращению отказов по общей причине оригинал документа
3.3 отказ (failure): Утрата изделием способности выполнять требуемую функцию.
Примечание - Обычно отказ является следствием неисправности одного или нескольких узлов машины.
Источник: ГОСТ Р ИСО 17359-2009: Контроль состояния и диагностика машин. Общее руководство по организации контроля состояния и диагностирования оригинал документа
3.16 отказ (failure): Отклонение реального функционирования от запланированного. [МЭК 61513, пункт 3.21, изменено]
Источник: ГОСТ Р МЭК 60880-2010: Атомные электростанции. Системы контроля и управления, важные для безопасности. Программное обеспечение компьютерных систем, выполняющих функции категории А оригинал документа
3.6.4 отказ (failure): Прекращение способности функционального блока выполнять необходимую функцию.
Примечания
1. Определение в МЭС 191-04-01 является идентичным, с дополнительными комментариями [ИСО/МЭК 2382-14-01-11].
2. Соотношение между сбоями и отказами в МЭК 61508 и МЭС 60050(191) см. на рисунке 4.
3. Характеристики требуемых функций неизбежно исключают определенные режимы работы, некоторые функции могут быть определены путем описания режимов, которых следует избегать. Возникновение таких режимов представляет собой отказ.
4. Отказы являются либо случайными (в аппаратуре), либо систематическими (в аппаратуре или в программном обеспечении), см. 3.6.5 и 3.6.6.

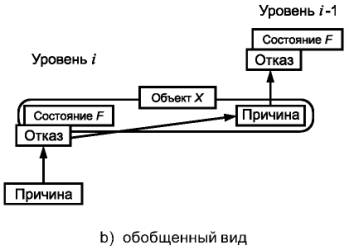
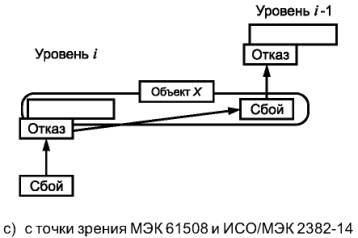
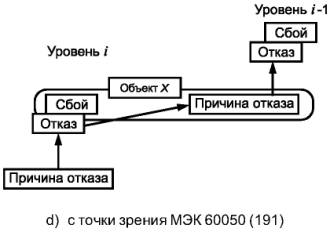
Примечания
1. Как показано на рисунке 4а), функциональный блок может быть представлен в виде многоуровневой иерархической конструкции, каждый из уровней которой может быть, в свою очередь, назван функциональным блоком. На уровне i «причина» может проявить себя как ошибка (отклонение от правильного значения или состояния) в пределах функционального блока, соответствующего данному уровню i. Если она не будет исправлена или нейтрализована, эта ошибка может привести к отказу данного функционального блока, который в результате перейдет в состояние F, в котором он более не может выполнять необходимую функцию (см. рисунок 4b)). Данное состояние F уровня i может в свою очередь проявиться в виде ошибки на уровне функционального блока i - 1, которая, если она не будет исправлена или нейтрализована, может привести к отказу функционального блока уровня i - 1.
2. В этой причинно-следственной цепочке один и тот же элемент («объект X») может рассматриваться как состояние F функционального блока уровня i, в которое он попадает в результате отказа, а также как причина отказа функционального блока уровня i - 1. Данный «объект X» объединяет концепцию «отказа» в МЭК 61508 и ИСО/МЭК 2382-14, в которой внимание акцентируется на причинном аспекте, как показано на рисунке 4с), и концепцию «отказа» из МЭС 60050(191), в которой основное внимание уделено аспекту состояния, как показано на рисунке 4d). В МЭС 60050(191) состояние F называется отказом, а в МЭК 61508 и ИСО/МЭК 2382-14 оно не определено.
3. В некоторых случаях отказ или ошибка могут быть вызваны внешним событием, таким как молния или электростатические помехи, а не внутренним отказом. Более того, ошибка (в обоих словарях) может возникать без предшествующего отказа. Примером такой ошибки может быть ошибка проектирования.
Рисунок 4 - Модель отказа
Источник: ГОСТ Р МЭК 61508-4-2007: Функциональная безопасность систем электрических, электронных, программируемых электронных, связанных с безопасностью. Часть 4. Термины и определения оригинал документа
3.21 отказ (failure): Отклонение реального функционирования от запланированного (см. рисунок 3). [МЭК 60880-2, пункт 3.8]
Примечание 1 - Отказ является результатом сбоя в аппаратуре, программном обеспечении, системе или ошибки оператора или обслуживания и отражается на прохождении сигнала.
Примечание 2 - См. также «дефект», «отказ программного обеспечения».
Источник: ГОСТ Р МЭК 61513-2011: Атомные станции. Системы контроля и управления, важные для безопасности. Общие требования оригинал документа
3.22 отказ (failure): Событие, заключающееся в нарушении работоспособного состояния элементов или систем платформы.
Источник: ГОСТ Р 54483-2011: Нефтяная и газовая промышленность. Платформы морские для нефтегазодобычи. Общие требования оригинал документа
3.1.7. отказ (fauit):
Состояние объекта, характеризуемое неспособностью выполнять требуемую функцию, за исключением состояний, связанных с предупредительным техническим обслуживанием или другими плановыми мероприятиями, или вследствие недостатка внешних ресурсов.
Примечание 1. - Отказ часто является результатом повреждения самого объекта, но может произойти и без предварительного повреждения объекта.
(МЭК 60204-1, п. 3.24).
Источник: ГОСТ Р МЭК 60519-1-2005: Безопасность электротермического оборудования. Часть 1. Общие требования оригинал документа
3.1.29 отказ (failure): Окончание способности изделия выполнять требуемую функцию.
Источник: ГОСТ Р 54828-2011: Комплектные распределительные устройства в металлической оболочке с элегазовой изоляцией (КРУЭ) на номинальные напряжения 110 кВ и выше. Общие технические условия оригинал документа
Русско-английский словарь нормативно-технической терминологии > отказ
-
4 технология коммутации
технология коммутации
-
[Интент]Современные технологии коммутации
[ http://www.xnets.ru/plugins/content/content.php?content.84]Статья подготовлена на основании материалов опубликованных в журналах "LAN", "Сети и системы связи", в книге В.Олифер и Н.Олифер "Новые технологии и оборудование IP-сетей", на сайтах www.citforum.ru и опубликована в журнале "Компьютерные решения" NN4-6 за 2000 год.
- Введение
- Коммутация первого уровня.
- Коммутация второго уровня.
- Коммутация третьего уровня.
- Коммутация четвертого уровня.
- Критерии выбора оборудования, физическая и логическая структура сети
- Качество обслуживания (QoS) и принципы задания приоритетов
- Заключение
Введение
На сегодня практически все организации, имеющие локальные сети, остановили свой выбор на сетях типа Ethernet. Данный выбор оправдан тем, что начало внедрения такой сети сопряжено с низкой стоимостью и простотой реализации, а развитие - с хорошей масштабируемостью и экономичностью.
Бросив взгляд назад - увидим, что развитие активного оборудования сетей шло в соответствии с требованиями к полосе пропускания и надежности. Требования, предъявляемые к большей надежности, привели к отказу от применения в качестве среды передачи коаксиального кабеля и перевода сетей на витую пару. В результате такого перехода отказ работы соединения между одной из рабочих станций и концентратором перестал сказываться на работе других рабочих станций сети. Но увеличения производительности данный переход не принес, так как концентраторы используют разделяемую (на всех пользователей в сегменте) полосу пропускания. По сути, изменилась только физическая топология сети - с общей шины на звезду, а логическая топология по-прежнему осталась - общей шиной.
Дальнейшее развитие сетей шло по нескольким путям:- увеличение скорости,
- внедрение сегментирования на основе коммутации,
- объединение сетей при помощи маршрутизации.
Увеличение скорости при прежней логической топологии - общая шина, привело к незначительному росту производительности в случае большого числа портов.
Большую эффективность в работе сети принесло сегментирование сетей с использованием технология коммутации пакетов. Коммутация наиболее действенна в следующих вариантах:
Вариант 1, именуемый связью "многие со многими" – это одноранговые сети, когда одновременно существуют потоки данных между парами рабочих станций. При этом предпочтительнее иметь коммутатор, у которого все порты имеют одинаковую скорость, (см. Рисунок 1).
Вариант 2, именуемый связью "один со многими" – это сети клиент-сервер, когда все рабочие станции работают с файлами или базой данных сервера. В данном случае предпочтительнее иметь коммутатор, у которого порты для подключения рабочих станций имеют одинаковую небольшую скорость, а порт, к которому подключается сервер, имеет большую скорость,(см. Рисунок 2).
Когда компании начали связывать разрозненные системы друг с другом, маршрутизация обеспечивала максимально возможную целостность и надежность передачи трафика из одной сети в другую. Но с ростом размера и сложности сети, а также в связи со все более широким применением коммутаторов в локальных сетях, базовые маршрутизаторы (зачастую они получали все данные, посылаемые коммутаторами) стали с трудом справляться со своими задачами.
Проблемы с трафиком, связанные с маршрутизацией, проявляются наиболее остро в средних и крупных компаниях, а также в деятельности операторов Internet, так как они вынуждены иметь дело с большими объемами IP-трафика, причем этот трафик должен передаваться своевременно и эффективно.
С подключением настольных систем непосредственно к коммутаторам на 10/100 Мбит/с между ними и магистралью оказывается все меньше промежуточных устройств. Чем выше скорость подключения настольных систем, тем более скоростной должна быть магистраль. Кроме того, на каждом уровне устройства должны справляться с приходящим трафиком, иначе возникновения заторов не избежать.
Рассмотрению технологий коммутации и посвящена данная статья.Коммутация первого уровня
Термин "коммутация первого уровня" в современной технической литературе практически не описывается. Для начала дадим определение, с какими характеристиками имеет дело физический или первый уровень модели OSI:
физический уровень определяет электротехнические, механические, процедурные и функциональные характеристики активации, поддержания и дезактивации физического канала между конечными системами. Спецификации физического уровня определяют такие характеристики, как уровни напряжений, синхронизацию изменения напряжений, скорость передачи физической информации, максимальные расстояния передачи информации, физические соединители и другие аналогичные характеристики.
Смысл коммутации на первом уровне модели OSI означает физическое (по названию уровня) соединение. Из примеров коммутации первого уровня можно привести релейные коммутаторы некоторых старых телефонных и селекторных систем. В более новых телефонных системах коммутация первого уровня применяется совместно с различными способами сигнализации вызовов и усиления сигналов. В сетях передачи данных данная технология применяется в полностью оптических коммутаторах.Коммутация второго уровня
Рассматривая свойства второго уровня модели OSI и его классическое определение, увидим, что данному уровню принадлежит основная доля коммутирующих свойств.
Определение. Канальный уровень (формально называемый информационно-канальным уровнем) обеспечивает надежный транзит данных через физический канал. Канальный уровень решает вопросы физической адресации (в противоположность сетевой или логической адресации), топологии сети, линейной дисциплины (каким образом конечной системе использовать сетевой канал), уведомления о неисправностях, упорядоченной доставки блоков данных и управления потоком информации.
На самом деле, определяемая канальным уровнем модели OSI функциональность служит платформой для некоторых из сегодняшних наиболее эффективных технологий. Большое значение функциональности второго уровня подчеркивает тот факт, что производители оборудования продолжают вкладывать значительные средства в разработку устройств с такими функциями.
С технологической точки зрения, коммутатор локальных сетей представляет собой устройство, основное назначение которого - максимальное ускорение передачи данных за счет параллельно существующих потоков между узлами сети. В этом - его главное отличие от других традиционных устройств локальных сетей – концентраторов (Hub), предоставляющих всем потокам данных сети всего один канал передачи данных.
Коммутатор позволяет передавать параллельно несколько потоков данных c максимально возможной для каждого потока скоростью. Эта скорость ограничена физической спецификацией протокола, которую также часто называют "скоростью провода". Это возможно благодаря наличию в коммутаторе большого числа центров обработки и продвижения кадров и шин передачи данных.
Коммутаторы локальных сетей в своем основном варианте, ставшем классическим уже с начала 90-х годов, работают на втором уровне модели OSI, применяя свою высокопроизводительную параллельную архитектуру для продвижения кадров канальных протоколов. Другими словами, ими выполняются алгоритмы работы моста, описанные в стандартах IEEE 802.1D и 802.1H. Также они имеют и много других дополнительных функций, часть которых вошла в новую редакцию стандарта 802.1D-1998, а часть остается пока не стандартизованной.
Коммутаторы ЛВС отличаются большим разнообразием возможностей и, следовательно, цен - стоимость 1 порта колеблется в диапазоне от 50 до 1000 долларов. Одной из причин столь больших различий является то, что они предназначены для решения различных классов задач. Коммутаторы высокого класса должны обеспечивать высокую производительность и плотность портов, а также поддерживать широкий спектр функций управления. Простые и дешевые коммутаторы имеют обычно небольшое число портов и не способны поддерживать функции управления. Одним из основных различий является используемая в коммутаторе архитектура. Поскольку большинство современных коммутаторов работают на основе патентованных контроллеров ASIC, устройство этих микросхем и их интеграция с остальными модулями коммутатора (включая буферы ввода-вывода) играет важнейшую роль. Контроллеры ASIC для коммутаторов ЛВС делятся на 2 класса - большие ASIC, способные обслуживать множество коммутируемых портов (один контроллер на устройство) и небольшие ASIC, обслуживающие по несколько портов и объединяемые в матрицы коммутации.
Существует 3 варианта архитектуры коммутаторов:
- переключение (cross-bar) с буферизацией на входе,
- самомаршрутизация (self-route) с разделяемой памятью
- высокоскоростная шина.
На рисунке 3 показана блок-схема коммутатора с архитектурой, используемой для поочередного соединения пар портов. В любой момент такой коммутатор может обеспечить организацию только одного соединения (пара портов). При невысоком уровне трафика не требуется хранение данных в памяти перед отправкой в порт назначения - такой вариант называется коммутацией на лету cut-through. Однако, коммутаторы cross-bar требуют буферизации на входе от каждого порта, поскольку в случае использования единственно возможного соединения коммутатор блокируется (рисунок 4). Несмотря на малую стоимость и высокую скорость продвижения на рынок, коммутаторы класса cross-bar слишком примитивны для эффективной трансляции между низкоскоростными интерфейсами Ethernet или token ring и высокоскоростными портами ATM и FDDI.
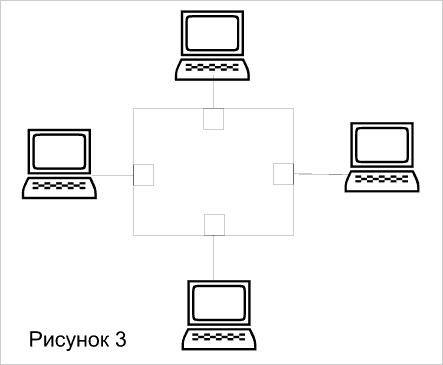
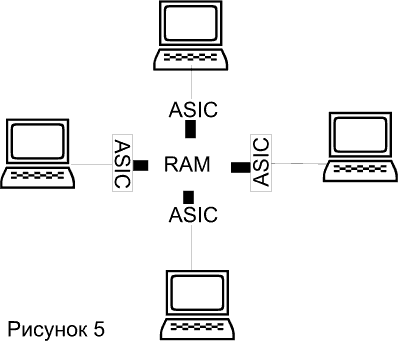
Коммутаторы с разделяемой памятью имеют общий входной буфер для всех портов, используемый как внутренняя магистраль устройства (backplane). Буферизагия данных перед их рассылкой (store-and-forward - сохранить и переслать) приводит к возникновению задержки. Однако, коммутаторы с разделяемой памятью, как показано на рисунке 5 не требуют организации специальной внутренней магистрали для передачи данных между портами, что обеспечивает им более низкую цену по сравнению с коммутаторами на базе высокоскоростной внутренней шины.
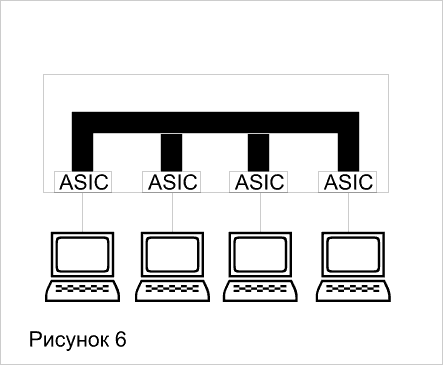
На рисунке 6 показана блок-схема коммутатора с высокоскоростной шиной, связывающей контроллеры ASIC. После того, как данные преобразуются в приемлемый для передачи по шине формат, они помещаются на шину и далее передаются в порт назначения. Поскольку шина может обеспечивать одновременную (паралельную) передачу потока данных от всех портов, такие коммутаторы часто называют "неблокируемыми" (non-blocking) - они не создают пробок на пути передачи данных.
Применение аналогичной параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня модели OSI.
Коммутация третьего уровня
В продолжении темы о технологиях коммутации рассмотренных в предыдущем номера повторим, что применение параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня. Это позволило существенно, в 10-100 раз повысить скорость маршрутизации по сравнению с традиционными маршрутизаторами, в которых один центральный универсальный процессор выполняет программное обеспечение маршрутизации.
По определению Сетевой уровень (третий) - это комплексный уровень, который обеспечивает возможность соединения и выбор маршрута между двумя конечными системами, подключенными к разным "подсетям", которые могут находиться в разных географических пунктах. В данном случае "подсеть" это, по сути, независимый сетевой кабель (иногда называемый сегментом).
Коммутация на третьем уровне - это аппаратная маршрутизация. Традиционные маршрутизаторы реализуют свои функции с помощью программно-управляемых процессоров, что будем называть программной маршрутизацией. Традиционные маршрутизаторы обычно продвигают пакеты со скоростью около 500000 пакетов в секунду. Коммутаторы третьего уровня сегодня работают со скоростью до 50 миллионов пакетов в секунду. Возможно и дальнейшее ее повышение, так как каждый интерфейсный модуль, как и в коммутаторе второго уровня, оснащен собственным процессором продвижения пакетов на основе ASIC. Так что наращивание количества модулей ведет к наращиванию производительности маршрутизации. Использование высокоскоростной технологии больших заказных интегральных схем (ASIC) является главной характеристикой, отличающей коммутаторы третьего уровня от традиционных маршрутизаторов. Коммутаторы 3-го уровня делятся на две категории: пакетные (Packet-by-Packet Layer 3 Switches, PPL3) и сквозные (Cut-Through Layer 3 Switches, CTL3). PPL3 - означает просто быструю маршрутизацию (Рисунок_7). CTL3 – маршрутизацию первого пакета и коммутацию всех остальных (Рисунок 8).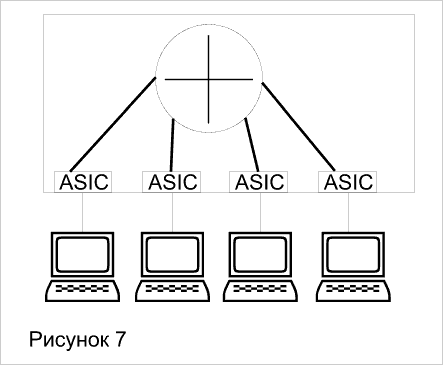
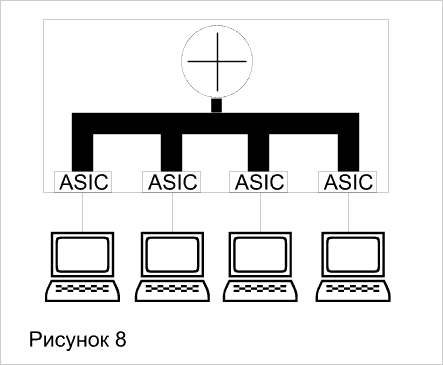
У коммутатора третьего уровня, кроме реализации функций маршрутизации в специализированных интегральных схемах, имеется несколько особенностей, отличающих их от традиционных маршрутизаторов. Эти особенности отражают ориентацию коммутаторов 3-го уровня на работу, в основном, в локальных сетях, а также последствия совмещения в одном устройстве коммутации на 2-м и 3-м уровнях:
- поддержка интерфейсов и протоколов, применяемых в локальных сетях,
- усеченные функции маршрутизации,
- обязательная поддержка механизма виртуальных сетей,
- тесная интеграция функций коммутации и маршрутизации, наличие удобных для администратора операций по заданию маршрутизации между виртуальными сетями.
Наиболее "коммутаторная" версия высокоскоростной маршрутизации выглядит следующим образом (рисунок 9). Пусть коммутатор третьего уровня построен так, что в нем имеется информация о соответствии сетевых адресов (например, IP-адресов) адресам физического уровня (например, MAC-адресам) Все эти МАС-адреса обычным образом отображены в коммутационной таблице, независимо от того, принадлежат ли они данной сети или другим сетям.
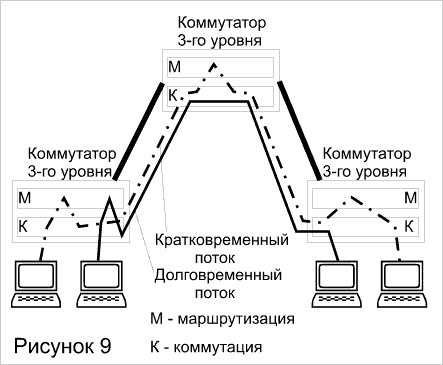
Первый коммутатор, на который поступает пакет, частично выполняет функции маршрутизатора, а именно, функции фильтрации, обеспечивающие безопасность. Он решает, пропускать или нет данный пакет в другую сеть Если пакет пропускать нужно, то коммутатор по IP-адресу назначения определяет МАС-адрес узла назначения и формирует новый заголовок второго уровня с найденным МАС-адресом. Затем выполняется обычная процедура коммутации по данному МАС-адресу с просмотром адресной таблицы коммутатора. Все последующие коммутаторы, построенные по этому же принципу, обрабатывают данный кадр как обычные коммутаторы второго уровня, не привлекая функций маршрутизации, что значительно ускоряет его обработку. Однако функции маршрутизации не являются для них избыточными, поскольку и на эти коммутаторы могут поступать первичные пакеты (непосредственно от рабочих станций), для которых необходимо выполнять фильтрацию и подстановку МАС-адресов.
Это описание носит схематический характер и не раскрывает способов решения возникающих при этом многочисленных проблем, например, проблемы построения таблицы соответствия IP-адресов и МАС-адресов
Примерами коммутаторов третьего уровня, работающих по этой схеме, являются коммутаторы SmartSwitch компании Cabletron. Компания Cabletron реализовала в них свой протокол ускоренной маршрутизации SecureFast Virtual Network, SFVN.
Для организации непосредственного взаимодействия рабочих станций без промежуточного маршрутизатора необходимо сконфигурировать каждую из них так, чтобы она считала собственный интерфейс маршрутизатором по умолчанию. При такой конфигурации станция пытается самостоятельно отправить любой пакет конечному узлу, даже если этот узел находится в другой сети. Так как в общем случае (см. рисунок 10) станции неизвестен МАС-адрес узла назначения, то она генерирует соответствующий ARP-запрос, который перехватывает коммутатор, поддерживающий протокол SFVN. В сети предполагается наличие сервера SFVN Server, являющегося полноценным маршрутизатором и поддерживающего общую ARP-таблицу всех узлов SFVN-сети. Сервер возвращает коммутатору МАС-адрес узла назначения, а коммутатор, в свою очередь, передает его исходной станции. Одновременно сервер SFVN передает коммутаторам сети инструкции о разрешении прохождения пакета с МАС-адресом узла назначения через границы виртуальных сетей. Затем исходная станция передает пакет в кадре, содержащем МАС-адрес узла назначения. Этот кадр проходит через коммутаторы, не вызывая обращения к их блокам маршрутизации. Отличие протокола SFVN компании Cabletron от - описанной выше общей схемы в том, что для нахождения МАС-адреса по IP-адресу в сети используется выделенный сервер.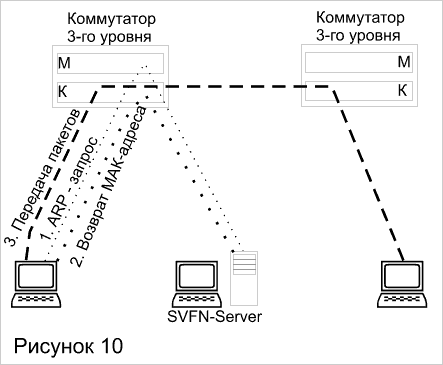
Протокол Fast IP компании 3Com является еще одним примером реализации подхода с отображением IP-адреса на МАС-адрес. В этом протоколе основными действующими лицами являются сетевые адаптеры (что не удивительно, так как компания 3Com является признанным лидером в производстве сетевых адаптеров Ethernet) С одной стороны, такой подход требует изменения программного обеспечения драйверов сетевых адаптеров, и это минус Но зато не требуется изменять все остальное сетевое оборудование.
При необходимости передать пакет узлу назначения другой сети, исходный узел в соответствии с технологией Fast IP должен передать запрос по протоколу NHRP (Next Hop Routing Protocol) маршрутизатору сети. Маршрутизатор переправляет этот запрос узлу назначения, как обычный пакет Узел назначения, который также поддерживает Fast IP и NHRP, получив запрос, отвечает кадром, отсылаемым уже не маршрутизатору, а непосредственно узлу-источнику (по его МАС-адресу, содержащемуся в NHRP-запросе). После этого обмен идет на канальном уровне на основе известных МАС-адресов. Таким образом, снова маршрутизировался только первый пакет потока (как на рисунке 9 кратковременный поток), а все остальные коммутировались (как на рисунке 9 долговременный поток).
Еще один тип коммутаторов третьего уровня — это коммутаторы, работающие с протоколами локальных сетей типа Ethernet и FDDI. Эти коммутаторы выполняют функции маршрутизации не так, как классические маршрутизаторы. Они маршрутизируют не отдельные пакеты, а потоки пакетов.
Поток — это последовательность пакетов, имеющих некоторые общие свойства. По меньшей мере, у них должны совпадать адрес отправителя и адрес получателя, и тогда их можно отправлять по одному и тому же маршруту. Если классический способ маршрутизации использовать только для первого пакета потока, а все остальные обрабатывать на основании опыта первого (или нескольких первых) пакетов, то можно значительно ускорить маршрутизацию всего потока.
Рассмотрим этот подход на примере технологии NetFlow компании Cisco, реализованной в ее маршрутизаторах и коммутаторах. Для каждого пакета, поступающего на порт маршрутизатора, вычисляется хэш-функция от IP-адресов источника, назначения, портов UDP или TCP и поля TOS, характеризующего требуемое качество обслуживания. Во всех маршрутизаторах, поддерживающих данную технологию, через которые проходит данный пакет, в кэш-памяти портов запоминается соответствие значения хэш-функции и адресной информации, необходимой для быстрой передачи пакета следующему маршрутизатору. Таким образом, образуется квазивиртуальный канал (см. Рисунок 11), который позволяет быстро передавать по сети маршрутизаторов все последующие пакеты этого потока. При этом ускорение достигается за счет упрощения процедуры обработки пакета маршрутизатором - не просматриваются таблицы маршрутизации, не выполняются ARP-запросы.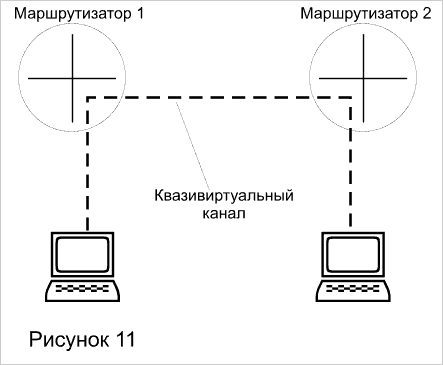
Этот прием может использоваться в маршрутизаторах, вообще не поддерживающих коммутацию, а может быть перенесен в коммутаторы. В этом случае такие коммутаторы тоже называют коммутаторами третьего уровня. Примеров маршрутизаторов, использующих данный подход, являются маршрутизаторы Cisco 7500, а коммутаторов третьего уровня — коммутаторы Catalyst 5000 и 5500. Коммутаторы Catalyst выполняют усеченные функции описанной схемы, они не могут обрабатывать первые пакеты потоков и создавать новые записи о хэш-функциях и адресной информации потоков. Они просто получают данную информацию от маршрутизаторов 7500 и обрабатывают пакеты уже распознанных маршрутизаторами потоков.
Выше был рассмотрен способ ускоренной маршрутизации, основанный на концепции потока. Его сущность заключается в создании квазивиртуальных каналов в сетях, которые не поддерживают виртуальные каналы в обычном понимании этого термина, то есть сетях Ethernet, FDDI, Token Ring и т п. Следует отличать этот способ от способа ускоренной работы маршрутизаторов в сетях, поддерживающих технологию виртуальных каналов — АТМ, frame relay, X 25. В таких сетях создание виртуального канала является штатным режимом работы сетевых устройств. Виртуальные каналы создаются между двумя конечными точками, причем для потоков данных, требующих разного качества обслуживания (например, для данных разных приложений) может создаваться отдельный виртуальный канал. Хотя время создания виртуального канала существенно превышает время маршрутизации одного пакета, выигрыш достигается за счет последующей быстрой передачи потока данных по виртуальному каналу. Но в таких сетях возникает другая проблема — неэффективная передача коротких потоков, то есть потоков, состоящих из небольшого количества пакетов (классический пример — пакеты протокола DNS).
Накладные расходы, связанные с созданием виртуального канала, приходящиеся на один пакет, снижаются при передаче объемных потоков данных. Однако они становятся неприемлемо высокими при передаче коротких потоков. Для того чтобы эффективно передавать короткие потоки, предлагается следующий вариант, при передаче нескольких первых пакетов выполняется обычная маршрутизация. Затем, после того как распознается устойчивый поток, для него строится виртуальный канал, и дальнейшая передача данных происходит с высокой скоростью по этому виртуальному каналу. Таким образом, для коротких потоков виртуальный канал вообще не создается, что и повышает эффективность передачи.
По такой схеме работает ставшая уже классической технология IP Switching компании Ipsilon. Для того чтобы сети коммутаторов АТМ передавали бы пакеты коротких потоков без установления виртуального канала, компания Ipsilon предложила встроить во все коммутаторы АТМ блоки IP-маршрутизации (рисунок 12), строящие обычные таблицы маршрутизации по обычным протоколам RIP и OSPF.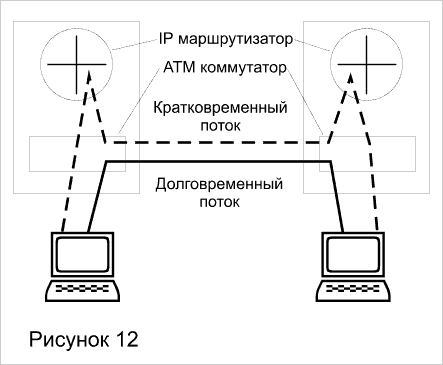
Компания Cisco Systems выдвинула в качестве альтернативы технологии IP Switching свою собственную технологию Tag Switching, но она не стала стандартной. В настоящее время IETF работает над стандартным протоколом обмена метками MPLS (Multi-Protocol Label Switching), который обобщает предложение компаний Ipsilon и Cisco, а также вносит некоторые новые детали и механизмы. Этот протокол ориентирован на поддержку качества обслуживания для виртуальных каналов, образованных метками.
Коммутация четвертого уровня
Свойства четвертого или транспортного уровня модели OSI следующие: транспортный уровень обеспечивает услуги по транспортировке данных. В частности, заботой транспортного уровня является решение таких вопросов, как выполнение надежной транспортировки данных через объединенную сеть. Предоставляя надежные услуги, транспортный уровень обеспечивает механизмы для установки, поддержания и упорядоченного завершения действия виртуальных каналов, систем обнаружения и устранения неисправностей транспортировки и управления информационным потоком (с целью предотвращения переполнения данными из другой системы).
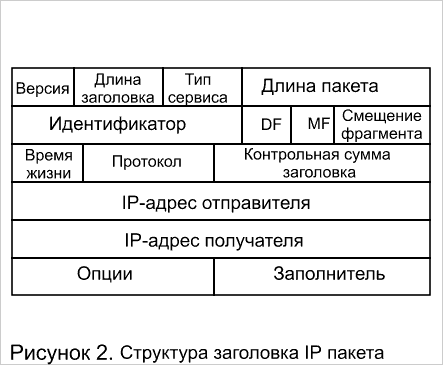
Некоторые производители заявляют, что их системы могут работать на втором, третьем и даже четвертом уровнях. Однако рассмотрение описания стека TCP/IP (рисунок 1), а также структуры пакетов IP и TCP (рисунки 2, 3), показывает, что коммутация четвертого уровня является фикцией, так как все относящиеся к коммутации функции осуществляются на уровне не выше третьего. А именно, термин коммутация четвертого уровня с точки зрения описания стека TCP/IP противоречий не имеет, за исключением того, что при коммутации должны указываться адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя. Пакеты TCP имеют поля локальный порт отправителя и локальный порт получателя (рисунок 3), несущие смысл точек входа в приложение (в программу), например Telnet с одной стороны, и точки входа (в данном контексте инкапсуляции) в уровень IP. Кроме того, в стеке TCP/IP именно уровень TCP занимается формированием пакетов из потока данных идущих от приложения. Пакеты IP (рисунок 2) имеют поля адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя и следовательно могут наряду с MAC адресами использоваться для коммутации. Тем не менее, название прижилось, к тому же практика показывает, что способность системы анализировать информацию прикладного уровня может оказаться полезной — в частности для управления трафиком. Таким образом, термин "зависимый от приложения" более точно отражает функции так называемых коммутаторов четвертого уровня.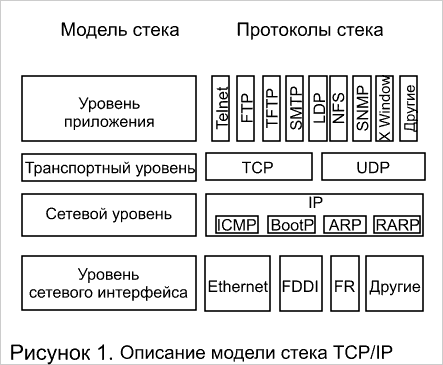
Тематики
EN
Русско-английский словарь нормативно-технической терминологии > технология коммутации
-
5 компонент
компонент
-
[IEV number 151-11-21]EN
component
constituent part of a device which cannot be physically divided into smaller parts without losing its particular function
[IEV number 151-11-21]FR
composant, m
partie constitutive d'un dispositif ne pouvant être fractionnée matériellement sans perdre sa fonction particulière
[IEV number 151-11-21]Тематики
- электротехника, основные понятия
EN
DE
FR
3.1 компонент (component): Часть, блок или сборочная единица, выполняющая определенную функцию в гидросистеме.
Примечание - Данное определение отличается от приведенного в ИСО 5598, поскольку включает соединители, трубы и шланги, которые исключены из определения ИСО 5598.
3.37 компонент (component): Элемент, рассматриваемый на самом низком уровне анализа системы.
Источник: ГОСТ Р 51901.6-2005: Менеджмент риска. Программа повышения надежности оригинал документа
3.3 компонент (component): Элемент, рассматриваемый на самом низком иерархическом уровне при анализе системы.
Источник: ГОСТ Р 51901.5-2005: Менеджмент риска. Руководство по применению методов анализа надежности оригинал документа
3.4 компонент (component): Любое изделие, имеющее существенное значение для безопасного функционирования оборудования и защитных систем, но не имеющее автономной функции.
3.6 компонент (component): Часть системы, которая поставляется изготовителем в готовом для продажи виде с упаковкой, маркировкой и сопроводительной информацией от изготовителя.
Примечание - Привязи и соединительные элементы являются примерами компонентов системы.
3.2 компонент (component): Часть системы, которая поставляется изготовителем в готовом для продажи виде с упаковкой, маркировкой и информацией, предоставляемой изготовителем.
Примечание - Привязи для удержания и позиционирования (включая поясные ремни) и стропы являются примерами компонентов систем. [ЕН 363:2002]
2.2 компонент (component): Часть системы, которая поставляется изготовителем в готовом для продажи виде с упаковкой, маркировкой и инструкцией по применению.
Примечание - Страховочная привязь и строп являются примерами компонентов системы.
3.2 компонент (component): Часть системы, которая поставляется изготовителем в готовом для продажи виде с упаковкой, маркировкой и инструкцией по применению.
Примечание - Страховочная привязь и строп являются примерами компонентов системы. [ЕН 363: 1992]
3.3 компонент (component): Составная часть газовой смеси, оказывающая влияние на служебные свойства и характеристики газовой смеси (например, в смеси, содержащей 11 % СО2 в аргоне, СО2 считают компонентом, а аргон - основным газом).
Источник: ГОСТ Р ИСО 14175-2010: Материалы сварочные. Газы и газовые смеси для сварки плавлением и родственных процессов оригинал документа
3.6 компонент (component): Сущность системы с дискретной структурой в рамках системы, которая взаимодействует с другими компонентами системы, дополняя тем самым систему свойствами и характеристиками на ее самом нижнем уровне.
[ИСО/МЭК 15288:2002]
Источник: ГОСТ Р ИСО 19439-2008: Интеграция предприятия. Основа моделирования предприятия оригинал документа
3.9 компонент (component): Одна из частей, из которых состоит система; компонент может представлять собой часть оборудования или программного обеспечения и может сам состоять из других компонентов.
[IEEE 610] [1]
Примечание 1 - См. также «система контроля и управления», «оборудование».
Примечание 2 - Термины «оборудование», «компонента» и «модуль» часто используют как взаимозаменяемые. Отношение между этими терминами пока не стандартизовано.
Источник: ГОСТ Р МЭК 61513-2011: Атомные станции. Системы контроля и управления, важные для безопасности. Общие требования оригинал документа
3.44 компонент (component): Сущность системы с дискретной структурой в рамках системы, которая взаимодействует с другими компонентами системы, дополняя тем самым систему свойствами и характеристиками на ее самом нижнем уровне.
Источник: ГОСТ Р 54136-2010: Системы промышленной автоматизации и интеграция. Руководство по применению стандартов, структура и словарь оригинал документа
Русско-английский словарь нормативно-технической терминологии > компонент
-
6 управление электропитанием
управление электропитанием
-
[Интент]
Управление электропитанием ЦОД
Автор: Жилкина Наталья
Опубликовано 23 апреля 2009 года
Источники бесперебойного питания, функционирующие в ЦОД, составляют важный элемент общей системы его энергообеспечения. Вписываясь в контур управления ЦОД, система мониторинга и управления ИБП становится ядром для реализации эксплуатационных функций.
Три задачи
Системы мониторинга, диагностики и управления питанием нагрузки решают три основные задачи: позволяют ИБП выполнять свои функции, оповещать персонал о происходящих с ними событиях и посылать команды для автоматического завершения работы защищаемого устройства.
Мониторинг параметров ИБП предполагает отображение и протоколирование состояния устройства и всех событий, связанных с его изменением. Диагностика реализуется функциями самотестирования системы. Управляющие же функции предполагают активное вмешательство в логику работы устройства.Многие специалисты этого рынка, отмечая важность процедуры мониторинга, считают, что управление должно быть сведено к минимуму. «Функция управления ИБП тоже нужна, но скорее факультативно, — говорит Сергей Ермаков, технический директор компании Inelt и эксперт в области систем Chloride. — Я глубоко убежден, что решения об активном управляющем вмешательстве в работу систем защиты электропитания ответственной нагрузки должен принимать человек, а не автоматизированная система. Завершение работы современных мощных серверов, на которых функционируют ответственные приложения, — это, как правило, весьма длительный процесс. ИБП зачастую не способны обеспечивать необходимое для него время, не говоря уж о времени запуска какого-то сервиса». Функция же мониторинга позволяет предотвратить наступление нежелательного события — либо, если таковое произошло, проанализировать его причины, опираясь не на слова, а на запротоколированные данные, хранящиеся в памяти адаптера или файлах на рабочей станции мониторинга.
Эту точку зрения поддерживает и Алексей Сарыгин, технический директор компании Radius Group: «Дистанционное управление мощных ИБП — это вопрос, к которому надо подходить чрезвычайно аккуратно. Если функции дистанционного мониторинга и диспетчеризации необходимы, то практика предоставления доступа персоналу к функциям дистанционного управления представляется радикально неверной. Доступность модулей управления извне потенциально несет в себе риск нарушения безопасности и категорически снижает надежность системы. Если существует физическая возможность дистанционно воздействовать на ИБП, на его параметры, отключение, снятие нагрузки, закрытие выходных тиристорных ключей или блокирование цепи байпаса, то это чревато потерей питания всего ЦОД».
Практически на всех трехфазных ИБП предусмотрена кнопка E.P.O. (Emergency Power Off), дублер которой может быть выведен на пульт управления диспетчерской. Она обеспечивает аварийное дистанционное отключение блоков ИБП при наступлении аварийных событий. Это, пожалуй, единственная возможность обесточить нагрузку, питаемую от трехфазного аппарата, но реализуется она в исключительных случаях.
Что же касается диагностики электропитания, то, как отмечает Юрий Копылов, технический директор московского офиса корпорации Eaton, в последнее время характерной тенденцией в управляющем программном обеспечении стал отказ от предоставления функций удаленного тестирования батарей даже системному администратору.
— Адекватно сравнивать состояние батарей необходимо под нагрузкой, — говорит он, — сам тест запускать не чаще чем раз в два дня, а разряжать батареи надо при одном и том же токе и уровне нагрузки. К тому же процесс заряда — довольно долгий. Все это не идет батареям на пользу.Средства мониторинга
Производители ИБП предоставляют, как правило, сразу несколько средств мониторинга и в некоторых случаях даже управления ИБП — все они основаны на трех основных методах.
В первом случае устройство подключается напрямую через интерфейс RS-232 (Com-порт) к консоли администратора. Дальность такого подключения не превышает 15 метров, но может быть увеличена с помощью конверторов RS-232/485 и RS-485/232 на концах провода, связывающего ИБП с консолью администратора. Такой способ обеспечивает низкую скорость обмена информацией и пригоден лишь для топологии «точка — точка».
Второй способ предполагает использование SNMP-адаптера — встроенной или внешней интерфейсной карты, позволяющей из любой точки локальной сети получить информацию об основных параметрах ИБП. В принципе, для доступа к ИБП через SNMP достаточно веб-браузера. Однако для большего комфорта производители оснащают свои системы более развитым графическим интерфейсом, обеспечивающим функции мониторинга и корректного завершения работы. На базе SNMP-протокола функционируют все основные системы мониторинга и управления ИБП, поставляемые штатно или опционально вместе с ИБП.
Стандартные SNMP-адаптеры поддерживают подключение нескольких аналоговых или пороговых устройств — датчик температуры, движения, открытия двери и проч. Интеграция таких устройств в общую систему мониторинга крупного объекта (например, дата-центра) позволяет охватить огромное количество точек наблюдения и отразить эту информацию на экране диспетчера.
Большое удобство предоставляет метод эксплуатационного удаленного контроля T.SERVICE, позволяющий отследить работу оборудования посредством телефонной линии (через модем GSM) или через Интернет (с помощью интерфейса Net Vision путем рассылки e-mail на электронный адрес потребителя). T.SERVICE обеспечивает диагностирование оборудования в режиме реального времени в течение 24 часов в сутки 365 дней в году. ИБП автоматически отправляет в центр технического обслуживания регулярные отчеты или отчеты при обнаружении неисправности. В зависимости от контролируемых параметров могут отправляться уведомления о неправильной эксплуатации (с пользователем связывается опытный специалист и рекомендует выполнить простые операции для предотвращения ухудшения рабочих характеристик оборудования) или о наличии отказа (пользователь информируется о состоянии устройства, а на место установки немедленно отправляется технический специалист).Профессиональное мнение
Наталья Маркина, коммерческий директор представительства компании SOCOMEC
Управляющее ПО фирмы SOCOMEC легко интегрируется в общий контур управления инженерной инфраструктурой ЦОД посредством разнообразных интерфейсов передачи данных ИБП. Установленное в аппаратной или ЦОД оборудование SOCOMEC может дистанционно обмениваться информацией о своих рабочих параметрах с системами централизованного управления и компьютерными сетями посредством сухих контактов, последовательных портов RS232, RS422, RS485, а также через интерфейс MODBUS TCP и GSS.
Интерфейс GSS предназначен для коммуникации с генераторными установками и включает в себя 4 входа (внешние контакты) и 1 выход (60 В). Это позволяет программировать особые процедуры управления, Global Supply System, которые обеспечивают полную совместимость ИБП с генераторными установками.
У компании Socomec имеется широкий выбор интерфейсов и коммуникационного программного обеспечения для установки диалога между ИБП и удаленными системами мониторинга промышленного и компьютерного оборудования. Такие опции связи, как панель дистанционного управления, интерфейс ADC (реконфигурируемые сухие контакты), обеспечивающий ввод и вывод данных при помощи сигналов сухих контактов, интерфейсы последовательной передачи данных RS232, RS422, RS485 по протоколам JBUS/MODBUS, PROFIBUS или DEVICENET, MODBUS TCP (JBUS/MODBUS-туннелирование), интерфейс NET VISION для локальной сети Ethernet, программное обеспечение TOP VISION для выполнения мониторинга с помощью рабочей станции Windows XP PRO — все это позволяет контролировать работу ИБП удобным для пользователя способом.
Весь контроль управления ИБП, ДГУ, контроль окружающей среды сводится в единый диспетчерский пункт посредством протоколов JBUS/MODBUS.
Индустриальный подход
Третий метод основан на использовании высокоскоростной индустриальной интерфейсной шины: CANBus, JBus, MODBus, PROFIBus и проч. Некоторые модели ИБП поддерживают разновидность универсального smart-слота для установки как карточек SNMP, так и интерфейсной шины. Система мониторинга на базе индустриальной шины может быть интегрирована в уже существующую промышленную SCADA-систему контроля и получения данных либо создана как заказное решение на базе многофункциональных стандартных контроллеров с выходом на шину. Промышленная шина через шлюзы передает информацию на удаленный диспетчерский пункт или в систему управления зданием (Building Management System, BMS). В эту систему могут быть интегрированы и контроллеры, управляющие ИБП.
Универсальные SCADA-системы поддерживают датчики и контроллеры широкого перечня производителей, но они недешевы и к тому же неудобны для внесения изменений. Но если подобная система уже функционирует на объекте, то интеграция в нее дополнительных ИБП не представляет труда.
Сергей Ермаков, технический директор компании Inelt, считает, что применение универсальных систем управления на базе промышленных контроллеров нецелесообразно, если используется для мониторинга только ИБП и ДГУ. Один из практичных подходов — создание заказной системы, с удобной для заказчика графической оболочкой и необходимым уровнем детализации — от карты местности до поэтажного плана и погружения в мнемосхему компонентов ИБП.
— ИБП может передавать одинаковое количество информации о своем состоянии и по прямому соединению, и по SNMP, и по Bus-шине, — говорит Сергей Ермаков. — Применение того или иного метода зависит от конкретной задачи и бюджета. Создав первоначально систему UPS Look для мониторинга ИБП, мы интегрировали в нее систему мониторинга ДГУ на основе SNMP-протокола, после чего по желанию одного из заказчиков конвертировали эту систему на промышленную шину Jbus. Новое ПО JSLook для мониторинга неограниченного количества ИБП и ДГУ по протоколу JBus является полнофункциональным средством мониторинга всей системы электроснабжения объекта.Профессиональное мение
Денис Андреев, руководитель департамента ИБП компании Landata
Практически все ИБП Eaton позволяют использовать коммуникационную Web-SNMP плату Connect UPS и датчик EMP (Environmental Monitoring Probe). Такой комплект позволяет в числе прочего осуществлять мониторинг температуры, влажности и состояния пары «сухих» контактов, к которым можно подключить внешние датчики.
Решение Eaton Environmental Rack Monitor представляет собой аналог такой связки, но с существенно более широким функционалом. Внешне эта система мониторинга температуры, влажности и состояния «сухих» контактов выполнена в виде компактного устройства, которое занимает минимум места в шкафу или в помещении.
Благодаря наличию у Eaton Environmental Rack Monitor (ERM) двух выходов датчики температуры или влажности можно разместить в разных точках стойки или помещения. Поскольку каждый из двух датчиков имеет еще по два сухих контакта, с них дополнительно можно принимать сигналы от датчиков задымления, утечки и проч. В центре обработки данных такая недорогая система ERM, состоящая из неограниченного количества датчиков, может транслировать информацию по протоколу SNMP в HTML-страницу и позволяет, не приобретая специального ПО, получить сводную таблицу измеряемых величин через веб-браузер.
Проблему дефицита пространства и высокой плотности размещения оборудования в серверных и ЦОД решают системы распределения питания линейки Eaton eDPU, которые можно установить как внутри стойки, так и на группу стоек.
Все модели этой линейки представляют четыре семейства: системы базового исполнения, системы с индикацией потребляемого тока, с мониторингом (локальным и удаленным, по сети) и управляемые, с возможностью мониторинга и управления электропитанием вплоть до каждой розетки. С помощью этих устройств можно компактным способом увеличить количество розеток в одной стойке, обеспечить контроль уровня тока и напряжения критичной нагрузки.
Контроль уровня потребляемой мощности может осуществляться с высокой степенью детализации, вплоть до сервера, подключенного к конкретной розетке. Это позволяет выяснить, какой сервер перегревается, где вышел из строя вентилятор, блок питания и т. д. Программным образом можно запустить сервер, подключенный к розетке ePDU. Интеграция системы контроля ePDU в платформу управления Eaton находится в процессе реализации.Требование объекта
Как поясняет Олег Письменский, в критичных объектах, таких как ЦОД, можно условно выделить две области контроля и управления. Первая, Grey Space, — это собственно здание и соответствующая система его энергообеспечения и энергораспределения. Вторая, White Space, — непосредственно машинный зал с его системами.
Выбор системы управления энергообеспечением ЦОД определяется типом объекта, требуемым функционалом системы управления и отведенным на эти цели бюджетом. В большинстве случаев кратковременная задержка между наступлением события и получением информации о нем системой мониторинга по SNMP-протоколу допустима. Тем не менее в целом ряде случаев, если характеристики объекта подразумевают непрерывность его функционирования, объект является комплексным и содержит большое количество элементов, требующих контроля и управления в реальном времени, ни одна стандартная система SNMP-мониторинга не обеспечит требуемого функционала. Для таких объектов применяют системы управления real-time, построенные на базе программно-аппаратных комплексов сбора данных, в том числе c функциями Softlogic.
Системы диспетчеризации и управления крупными объектами реализуются SCADA-системами, широкий перечень которых сегодня присутствует на рынке; представлены они и в портфеле решений Schneider Electric. Тип SCADA-системы зависит от класса и размера объекта, от количества его элементов, требующих контроля и управления, от уровня надежности. Частный вид реализации SCADA — это BMS-система(Building Management System).
«Дата-центры с объемом потребляемой мощности до 1,5 МВт и уровнем надежности Tier I, II и, с оговорками, даже Tier III, могут обслуживаться без дополнительной SCADA-системы, — говорит Олег Письменский. — На таких объектах целесообразно применять ISX Central — программно-аппаратный комплекс, использующий SNMP. Если же категория и мощность однозначно предполагают непрерывность управления, в таких случаях оправданна комбинация SNMP- и SCADA-системы. Например, для машинного зала (White Space) применяется ISX Central с возможными расширениями как Change & Capacity Manager, в комбинации со SCADA-системой, управляющей непосредственно объектом (Grey Space)».Профессиональное мнение
Олег Письменский, директор департамента консалтинга APC by Schneider Electric в России и СНГ
Подход APC by Schneider Electric к реализации полномасштабного полноуправляемого и надежного ЦОД изначально был основан на базисных принципах управления ИТ-инфраструктурой в рамках концепции ITIL/ITSM. И история развития системы управления инфраструктурой ЦОД ISX Manager, которая затем интегрировалась с программно-аппаратным комплексом NetBotz и трансформировалась в портал диспетчеризации ISX Central, — лучшее тому доказательство.
Первым итогом поэтапного приближения к намеченной цели стало наращивание функций контроля параметров энергообеспечения. Затем в этот контур подключилась система управления кондиционированием, система контроля параметров окружающей среды. Очередным шагом стало измерение скорости воздуха, влажности, пыли, радиации, интеграция сигналов от камер аудио- и видеонаблюдения, системы управления блоками розеток, завершения работы сервера и т. д.
Эта система не может и не должна отвечать абсолютно всем принципам ITSM, потому что не все они касаются существа поставленной задачи. Но как только в отношении политик и некоторых тактик управления емкостью и изменениями в ЦОД потребовался соответствующий инструментарий — это нашло отражение в расширении функционала ISX Central, который в настоящее время реализуют ПО APC by Schneider Electric Capacity Manager и APC by Schneider Electric Change Manager. С появлением этих двух решений, интегрированных в систему управления реальным объектом, АРС предоставляет возможность службе эксплуатации оптимально планировать изменения количественного и качественного состава оборудования машинного зала — как на ежедневном оперативном уровне, так и на уровне стратегических задач массовых будущих изменений.
Решение APC by Schneider Electric Capacity обеспечивает автоматизированную обработку информации о свободных ресурсах инженерной инфраструктуры, реальном потреблении мощности и пространстве в стойках. Обращаясь к серверу ISX Central, системы APC by Schneider Electric Capacity Manager и APC by Schneider Electric Change Manager оценивают степень загрузки ИБП и систем охлаждения InRow, прогнозируют воздействие предполагаемых изменений и предлагают оптимальное место для установки нового или перестановки имеющегося оборудования. Новые решения позволяют, выявив последствия от предполагаемых изменений, правильно спланировать замену оборудования в ЦОД.
Переход от частного к общему может потребовать интеграции ISX Central в такие, например, порталы управления, как Tivoli или Open View. Возможны и другие сценарии, когда ISX Central вписывается и в SCADA–систему. В этом случае ISX Central выполняет роль диспетчерской настройки, функционал которой распространяется на серверную комнату, но не охватывает целиком периметр объекта.Случай из практики
Решение задачи управления энергообеспечением ЦОД иногда вступает в противоречие с правилами устройств электроустановок (ПУЭ). Может оказаться, что в соответствии с ПУЭ в ряде случаев (например, при компоновке щитов ВРУ) необходимо обеспечить механические блокировки. Однако далеко не всегда это удается сделать. Поэтому такая задача часто требует нетривиального решения.
— В одном из проектов, — вспоминает Алексей Сарыгин, — где система управления включала большое количество точек со взаимными пересечениями блокировок, требовалось не допустить снижения общей надежности системы. В этом случае мы пришли к осознанному компромиссу, сделали систему полуавтоматической. Там, где это было возможно, присутствовали механические блокировки, за пультом дежурной смены были оставлены функции мониторинга и анализа, куда сводились все данные о положении всех автоматов. Но исполнительную часть вывели на отдельную панель управления уже внутри ВРУ, где были расположены подробные пользовательские инструкции по оперативному переключению. Таким образом мы избавились от излишней автоматизации, но постарались минимизировать потери в надежности и защититься от ошибок персонала.
[ http://www.computerra.ru/cio/old/products/infrastructure/421312/]Тематики
EN
Русско-английский словарь нормативно-технической терминологии > управление электропитанием
-
7 сегментация прикладной программы
сегментация прикладной программы
Разделение сложной прикладной программы на части.
Сегментация осуществляется с помощью специального инструментального программного обеспечения, которое автоматизирует рассматриваемый процесс. При необходимости в сети прикладная программа делится на самостоятельные части, загружаемые в различные оконечные системы. Создается возможность перемещения программ из одной системы в другую и распределенной обработки данных.
В результате сегментации каждая выделенная часть программы включает управление данными, алгоритм и блок презентации. Благодаря этому, она может быть оптимальным образом выполнена на основе используемых платформ.
[ http://www.morepc.ru/dict/]Тематики
EN
Русско-английский словарь нормативно-технической терминологии > сегментация прикладной программы
-
8 язык FBD
язык FBD
Диаграмма функциональных блоков. Один из пяти стандартизированных языков программирования ПЛК.
[ http://kazanets.narod.ru/PLC_PART2.htm]Язык FBD (Functional Block Diagram, Диаграмма Функциональных Блоков) является языком графического программирования, так же, как и LD, использующий аналогию с электрической (электронной) схемой. Программа на языке FBD представляет собой совокупность функциональных блоков (functional flocks, FBs), входы и выходы которых соединены линиями связи ( connections). Эти связи, соединяющие выходы одних блоков с входами других, являются по сути дела переменными программы и служат для пересылки данных между блоками. Каждый блок представляет собой математическую операцию (сложение, умножение, триггер, логическое “или” и т.д.) и может иметь, в общем случае, произвольное количество входов и выходов. Начальные значения переменных задаются с помощью специальных блоков – входов или констант, выходные цепи могут быть связаны либо с физическими выходами контроллера, либо с глобальными переменными программы. Пример фрагмента программы на языке FBD приведен на рис. 2.
Практика показывает, что FBD является наиболее распространенным языком стандарта IEC. Графическая форма представления алгоритма, простота в использовании, повторное использование функциональных диаграмм и библиотеки функциональных блоков делают язык FBD незаменимым при разработке программного обеспечения ПЛК. Вместе с тем, нельзя не заметить и некоторые недостатки FBD. Хотя FBD обеспечивает легкое представление функций обработки как «непрерывных» сигналов, в частности, функций регулирования, так и логических функций, в нем неудобным и неочевидным образом реализуются те участки программы, которые было бы удобно представить в виде конечного автомата.
Рис.2. Функциональная схема FBD.[ http://kazanets.narod.ru/PLC_PART2.htm]
Тематики
EN
Русско-английский словарь нормативно-технической терминологии > язык FBD
-
9 человеко-машинный интерфейс
- operator-machine communication
- MMI
- man-machine interface
- man-machine communication
- human-machine interface
- human-computer interface
- human interface device
- human interface
- HMI
- computer human interface
- CHI
человеко-машинный интерфейс (ЧМИ)
Технические средства, предназначенные для обеспечения непосредственного взаимодействия между оператором и оборудованием и дающие возможность оператору управлять оборудованием и контролировать его функционирование.
Примечание
Такие средства могут включать приводимые в действие вручную органы управления, контрольные устройства, дисплеи.
[ ГОСТ Р МЭК 60447-2000]
человекомашинный интерфейс (ЧМИ)
Технические средства контроля и управления, являющиеся частью оборудования, предназначенные для обеспечения непосредственного взаимодействия между оператором и оборудованием и дающие возможность оператору управлять оборудованием и контролировать его функционирование (ГОСТ Р МЭК 60447).
Примечание
Такие средства могут включать приводимые в действие вручную органы управления, контрольные устройства и дисплеи.
[ ГОСТ Р МЭК 60073-2000]
человеко-машинный интерфейс
Средства обеспечения двусторонней связи "оператор - технологическое оборудование" (АСУ ТП). Название класса средств, в который входят подклассы:
SCADA (Supervisory Control and Data Acquisition) - Операторское управление и сбор данных от технологического оборудования.
DCS (Distributed Control Systems) - Распределенная система управления технологическим оборудованием.
[ http://www.morepc.ru/dict/]Параллельные тексты EN-RU
MotorSys™ iPMCC solutions can integrate a dedicated human-machine interface (HMI) or communicate via a personal computer directly on the motor starters.
[Schneider Electric]Интеллектуальный центр распределения электроэнергии и управления электродвигателями MotorSys™ может иметь в своем составе специальный человеко-машинный интерфейс (ЧМИ). В качестве альтернативы используется обмен данным между персональным компьютером и пускателями.
[Перевод Интент]
HMI на базе операторских станций
Самое, пожалуй, главное в системе управления - это организация взаимодействия между человеком и программно-аппаратным комплексом. Обеспечение такого взаимодействия и есть задача человеко-машинного интерфейса (HMI, human machine interface).
На мой взгляд, в аббревиатуре “АСУ ТП” ключевым является слово “автоматизированная”, что подразумевает непосредственное участие человека в процессе реализации системой определенных задач. Очевидно, что чем лучше организован HMI, тем эффективнее человек сможет решать поставленные задачи.
Как же организован HMI в современных АСУ ТП?
Существует, как минимум, два подхода реализации функционала HMI:- На базе специализированных рабочих станций оператора, устанавливаемых в центральной диспетчерской;
- На базе панелей локального управления, устанавливаемых непосредственно в цеху по близости с контролируемым технологическим объектам.
Иногда эти два варианта комбинируют, чтобы достичь наибольшей гибкости управления. В данной статье речь пойдет о первом варианте организации операторского уровня.
Аппаратно рабочая станция оператора (OS, operator station) представляет собой ни что иное как персональный компьютер. Как правило, станция снабжается несколькими широкоэкранными мониторами, функциональной клавиатурой и необходимыми сетевыми адаптерами для подключения к сетям верхнего уровня (например, на базе Industrial Ethernet). Станция оператора несколько отличается от привычных для нас офисных компьютеров, прежде всего, своим исполнением и эксплуатационными характеристиками (а также ценой 4000 - 10 000 долларов).
На рисунке 1 изображена рабочая станция оператора системы SIMATIC PCS7 производства Siemens, обладающая следующими техническими характеристиками:
Процессор: Intel Pentium 4, 3.4 ГГц;
Память: DDR2 SDRAM до 4 ГБ;
Материнская плата: ChipSet Intel 945G;
Жесткий диск: SATA-RAID 1/2 x 120 ГБ;
Слоты: 4 x PCI, 2 x PCI E x 1, 1 x PCI E x 16;
Степень защиты: IP 31;
Температура при эксплуатации: 5 – 45 C;
Влажность: 5 – 95 % (без образования конденсата);
Операционная система: Windows XP Professional/2003 Server.
Рис. 1. Пример промышленной рабочей станции оператора.Системный блок может быть как настольного исполнения ( desktop), так и для монтажа в 19” стойку ( rack-mounted). Чаще применяется второй вариант: системный блок монтируется в запираемую стойку для лучшей защищенности и предотвращения несанкционированного доступа.
Какое программное обеспечение используется?
На станции оператора устанавливается программный пакет визуализации технологического процесса (часто называемый SCADA). Большинство пакетов визуализации работают под управлением операционных систем семейства Windows (Windows NT 4.0, Windows 2000/XP, Windows 2003 Server), что, на мой взгляд, является большим минусом.
Программное обеспечение визуализации призвано выполнять следующие задачи:- Отображение технологической информации в удобной для человека графической форме (как правило, в виде интерактивных мнемосхем) – Process Visualization;
- Отображение аварийных сигнализаций технологического процесса – Alarm Visualization;
- Архивирование технологических данных (сбор истории процесса) – Historical Archiving;
- Предоставление оператору возможности манипулировать (управлять) объектами управления – Operator Control.
- Контроль доступа и протоколирование действий оператора – Access Control and Operator’s Actions Archiving.
- Автоматизированное составление отчетов за произвольный интервал времени (посменные отчеты, еженедельные, ежемесячные и т.д.) – Automated Reporting.
Как правило, SCADA состоит из двух частей:
- Среды разработки, где инженер рисует и программирует технологические мнемосхемы;
- Среды исполнения, необходимой для выполнения сконфигурированных мнемосхем в режиме runtime. Фактически это режим повседневной эксплуатации.
Существует две схемы подключения операторских станций к системе управления, а точнее уровню управления. В рамках первой схемы каждая операторская станция подключается к контроллерам уровня управления напрямую или с помощью промежуточного коммутатора (см. рисунок 2). Подключенная таким образом операторская станция работает независимо от других станций сети, и поэтому часто называется одиночной (пусть Вас не смущает такое название, на самом деле таких станций в сети может быть несколько).
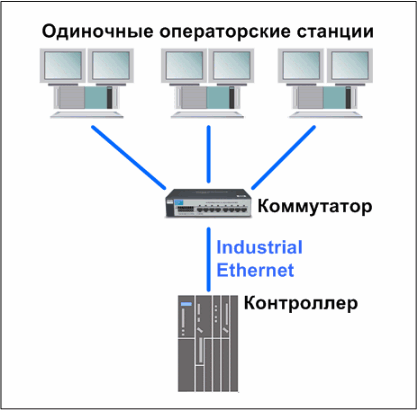
Рис. 2. Схема подключения одиночных операторских станций к уровню управления.Есть и другой вариант. Часто операторские станции подключают к серверу или резервированной паре серверов, а серверы в свою очередь подключаются к промышленным контроллерам. Таким образом, сервер, являясь неким буфером, постоянно считывает данные с контроллера и предоставляет их по запросу рабочим станциям. Станции, подключенные по такой схеме, часто называют клиентами (см. рисунок 3).
Как происходит информационный обмен?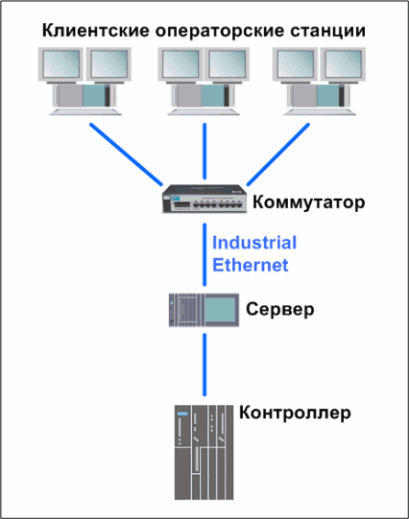
Рис. 3. Клиент-серверная архитектура операторского уровня.
Для сопряжения операторской станции с промышленным контроллером на первой устанавливается специальное ПО, называемое драйвером ввода/вывода. Драйвер ввода/вывода поддерживает совместимый с контроллером коммуникационный протокол и позволяет прикладным программам считывать с контроллера параметры или наоборот записывать в него. Пакет визуализации обращается к драйверу ввода/вывода каждый раз, когда требуется обновление отображаемой информации или запись измененных оператором данных. Для взаимодействия пакета визуализации и драйвера ввода/вывода используется несколько протоколов, наиболее популярные из которых OPC (OLE for Process Control) и NetDDE (Network Dynamic Data Exchange). Обобщенно можно сказать, что OPC и NetDDE – это протоколы информационного обмена между различными приложениями, которые могут выполняться как на одном, так и на разных компьютерах. На рисунках 4 и 5 изображено, как взаимодействуют программные компоненты при различных схемах построения операторского уровня.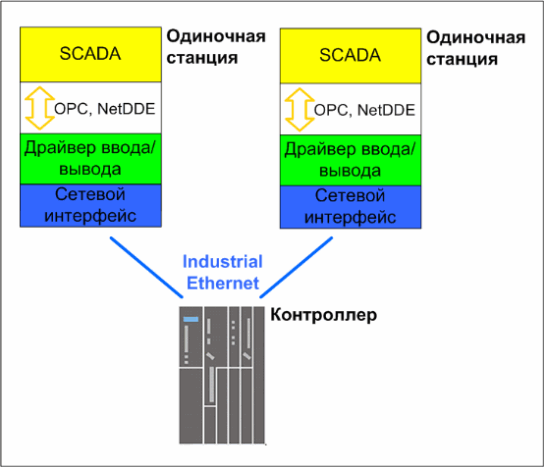
Рис. 4. Схема взаимодействия программных модулей при использовании одиночных станций.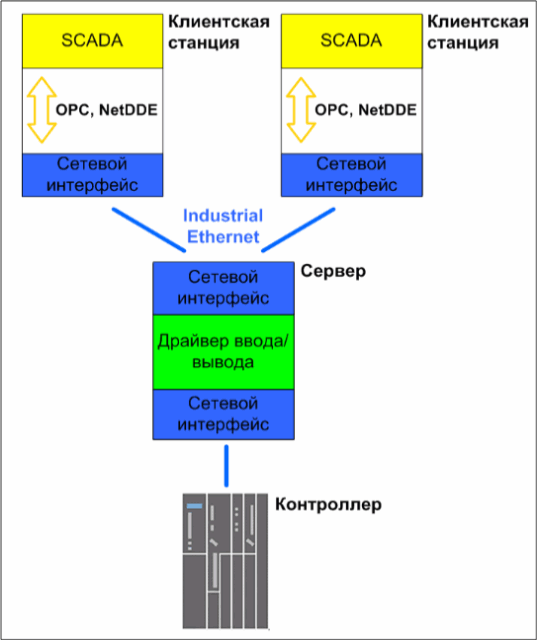
Рис. 5. Схема взаимодействия программных модулей при использовании клиент-серверной архитектуры.
Как выглядит SCADA?
Разберем простой пример. На рисунке 6 приведена абстрактная схема технологического процесса, хотя полноценным процессом это назвать трудно.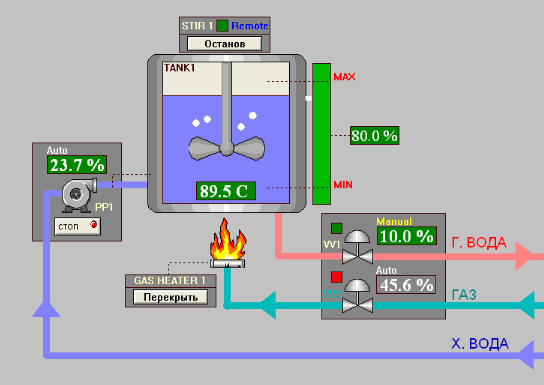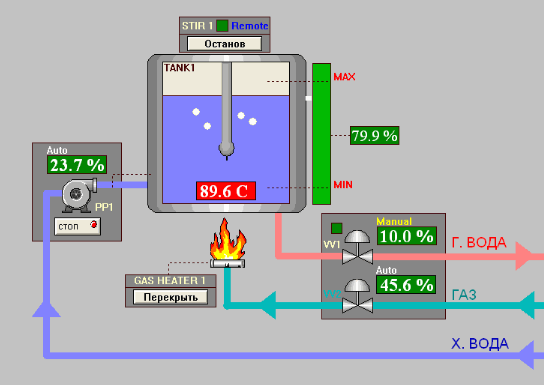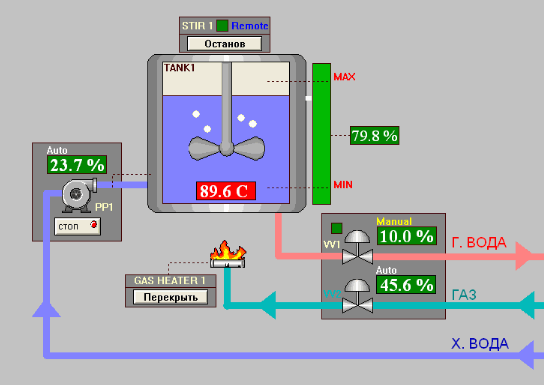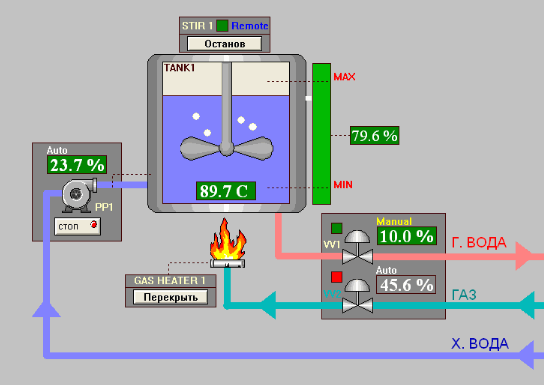 Рис. 6. Пример операторской мнемосхемы.
Рис. 6. Пример операторской мнемосхемы.
На рисунке 6 изображен очень упрощенный вариант операторской мнемосхемы для управления тех. процессом. Как видно, резервуар (емкость) наполняется водой. Задача системы - нагреть эту воду до определенной температуры. Для нагрева воды используется газовая горелка. Интенсивность горения регулируется клапаном подачи газа. Также должен быть насос для закачки воды в резервуар и клапан для спуска воды.
На мнемосхеме отображаются основные технологические параметры, такие как: температура воды; уровень воды в резервуаре; работа насосов; состояние клапанов и т.д. Эти данные обновляются на экране с заданной частотой. Если какой-либо параметр достигает аварийного значения, соответствующее поле начинает мигать, привлекая внимание оператора.
Сигналы ввода/вывода и исполнительные механизмы отображаются на мнемосхемах в виде интерактивных графических символов (иконок). Каждому типу сигналов и исполнительных механизмов присваивается свой символ: для дискретного сигнала это может быть переключатель, кнопка или лампочка; для аналогового – ползунок, диаграмма или текстовое поле; для двигателей и насосов – более сложные фейсплейты ( faceplates). Каждый символ, как правило, представляет собой отдельный ActiveX компонент. Вообще технология ActiveX широко используется в SCADA-пакетах, так как позволяет разработчику подгружать дополнительные символы, не входящие в стандартную библиотеку, а также разрабатывать свои собственные графические элементы, используя высокоуровневые языки программирования.
Допустим, оператор хочет включить насос. Для этого он щелкает по его иконке и вызывает панель управления ( faceplate). На этой панели он может выполнить определенные манипуляции: включить или выключить насос, подтвердить аварийную сигнализацию, перевести его в режим “техобслуживания” и т.д. (см. рисунок 7). Рис. 7. Пример фейсплейта для управления насосом.Оператор также может посмотреть график изменения интересующего его технологического параметра, например, за прошедшую неделю. Для этого ему надо вызвать тренд ( trend) и выбрать соответствующий параметр для отображения. Пример тренда реального времени показан на рисунке 8.
Рис. 7. Пример фейсплейта для управления насосом.Оператор также может посмотреть график изменения интересующего его технологического параметра, например, за прошедшую неделю. Для этого ему надо вызвать тренд ( trend) и выбрать соответствующий параметр для отображения. Пример тренда реального времени показан на рисунке 8.
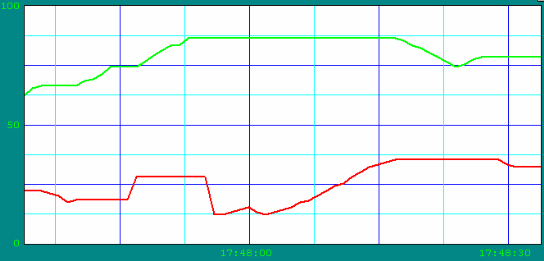 Рис. 8. Пример отображения двух параметров на тренде реального времени.
Рис. 8. Пример отображения двух параметров на тренде реального времени.
Для более детального обзора сообщений и аварийных сигнализаций оператор может воспользоваться специальной панелью ( alarm panel), пример которой изображен на рисунке 9. Это отсортированный список сигнализаций (alarms), представленный в удобной для восприятия форме. Оператор может подтвердить ту или иную аварийную сигнализацию, применить фильтр или просто ее скрыть.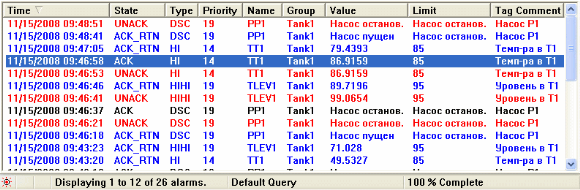 Рис. 9. Панель сообщений и аварийных сигнализаций.
Рис. 9. Панель сообщений и аварийных сигнализаций.
Говоря о SCADA, инженеры часто оперируют таким важным понятием как “тэг” ( tag). Тэг является по существу некой переменной программы визуализации и может быть использован как для локального хранения данных внутри программы, так и в качестве ссылки на внешний параметр процесса. Тэги могут быть разных типов, начиная от обычных числовых данных и кончая структурой с множеством полей. Например, один визуализируемый параметр ввода/вывода – это тэг, или функциональный блок PID-регулятора, выполняемый внутри контроллера, - это тоже тэг. Ниже представлена сильно упрощенная структура тэга, соответствующего простому PID-регулятору:
Tag Name = “MyPID”;
Tag Type = PID;
Fields (список параметров):
MyPID.OP
MyPID.SP
MyPID.PV
MyPID.PR
MyPID.TI
MyPID.DI
MyPID.Mode
MyPID.RemoteSP
MyPID.Alarms и т.д.
В комплексной прикладной программе может быть несколько тысяч тэгов. Производители SCADA-пакетов это знают и поэтому применяют политику лицензирования на основе количества используемых тэгов. Каждая купленная лицензия жестко ограничивает суммарное количество тэгов, которые можно использовать в программе. Очевидно, чем больше тегов поддерживает лицензия, тем дороже она стоит; так, например, лицензия на 60 000 тэгов может обойтись в 5000 тыс. долларов или даже дороже. В дополнение к этому многие производители SCADA формируют весьма существенную разницу в цене между “голой” средой исполнения и полноценной средой разработки; естественно, последняя с таким же количеством тэгов будет стоить заметно дороже.
Сегодня на рынке представлено большое количество различных SCADA-пакетов, наиболее популярные из которых представлены ниже:
1. Wonderware Intouch;
2. Simatic WinCC;
3. Iconics Genesis32;
4. Citect;
5. Adastra Trace Mode
Лидирующие позиции занимают Wonderware Intouch (производства Invensys) и Simatic WinCC (разработки Siemens) с суммарным количеством инсталляций более 80 тыс. в мире. Пакет визуализации технологического процесса может поставляться как в составе комплексной системы управления, так и в виде отдельного программного продукта. В последнем случае SCADA комплектуется набором драйверов ввода/вывода для коммуникации с контроллерами различных производителей. [ http://kazanets.narod.ru/HMI_PART1.htm]Тематики
- автоматизация, основные понятия
- автоматизированные системы
Синонимы
EN
Русско-английский словарь нормативно-технической терминологии > человеко-машинный интерфейс
См. также в других словарях:
Перечень школьного программного обеспечения — Содержание 1 Бразилия 2 Великобритания 3 Индия … Википедия
Легализация программного обеспечения — Легализация ПО это отказ от «пиратского» использования программ, переход с использования проприетарного программного обеспечения, не сопровождаемого лицензиями (то есть разрешениями на использование этого ПО от его владельца или… … Википедия
Спецификация программного обеспечения — Спецификация требований программного обеспечения (англ. Software Requirements Specification, SRS) законченное описание поведения программы, которую требуется разработать. Включает ряд пользовательских сценариев (англ. use… … Википедия
Проектирование программного обеспечения — Разработка программного обеспечения Процесс разработки ПО Шаги процесса Анализ • Проектирование • Программирование • … Википедия
ГОСТ Р 52980-2008: Системы промышленной автоматизации и их интеграция. Системы программируемые электронные железнодорожного применения. Требования к программному обеспечению — Терминология ГОСТ Р 52980 2008: Системы промышленной автоматизации и их интеграция. Системы программируемые электронные железнодорожного применения. Требования к программному обеспечению оригинал документа: 3.1 автоматическая локомотивная… … Словарь-справочник терминов нормативно-технической документации
блок моделируемого объекта автоматизированной системы прогнозирования — блок моделируемого объекта автоматизированной системы прогнозирования; блок моделируемого объекта Совокупность элементов программного и информационного обеспечения (обеспечивающих средств) автоматизированной системы прогнозирования,… … Политехнический терминологический толковый словарь
блок моделируемого фона автоматизированной системы прогнозирования — блок моделируемого фона автоматизированной системы прогнозирования; блок моделируемого фона Совокупность элементов программного и информационного обеспечения (обеспечивающих средств) автоматизированной системы прогнозирования, представляющих… … Политехнический терминологический толковый словарь
блок моделируемого объекта — автоматизированной системы прогнозирования; блок моделируемого объекта Совокупность элементов программного и информационного обеспечения (обеспечивающих средств) автоматизированной системы прогнозирования, представляющих объект прогнозирования и… … Политехнический терминологический толковый словарь
блок моделируемого фона — автоматизированной системы прогнозирования; блок моделируемого фона Совокупность элементов программного и информационного обеспечения (обеспечивающих средств) автоматизированной системы прогнозирования, представляющих прогнозный фон и дающих… … Политехнический терминологический толковый словарь
ГОСТ Р 53802-2010: Системы и комплексы космические. Термины и определения — Терминология ГОСТ Р 53802 2010: Системы и комплексы космические. Термины и определения оригинал документа: 5 авиационный космический комплекс; АКК: Космический комплекс, в котором средством выведения и стартовым комплексом орбитальных технических … Словарь-справочник терминов нормативно-технической документации
ГОСТ Р 54136-2010: Системы промышленной автоматизации и интеграция. Руководство по применению стандартов, структура и словарь — Терминология ГОСТ Р 54136 2010: Системы промышленной автоматизации и интеграция. Руководство по применению стандартов, структура и словарь оригинал документа: 4.1 абстрактная деталь (abstract part): Деталь, которая определена только своей… … Словарь-справочник терминов нормативно-технической документации
 18+© Академик, 2000-2024
18+© Академик, 2000-2024- Обратная связь: Техподдержка, Реклама на сайте
Экспорт словарей на сайты, сделанные на PHP, Joomla, Drupal, WordPress, MODx.
Перевод: с русского на английский
с английского на русский- С английского на:
- Русский
- С русского на:
- Все языки
- Английский
- Немецкий